记Filebeat系统资源使用优化
本文重点:
本文将着重关注filebeat,在filebeat在生产部署后,必定会对服务CPU、内存、网络有影响,如果将这些因素都在可控范围内,那是完全可以接受的。但是可能由于我们的配置不合理,或者非预期的情况导致CPU、内存占用过大,势必会影响到同在一起的业务应用稳定性。
如今企业应用分布式、微服务盛行,针对分布于多节点的日志,会使用分布式日志系统架构,来满足业务开发查询多节点的日志并进行问题排查和定位。迄今为止,最为通用和成熟的就是elastic的ELK架构,我司现在也是按照如下通用架构(本文使用7.2版本的elastic套件):
- filebeat(本文重点):日志采集器,启动于业务服务器进行日志采集,并发送到kafka指定topic
- kafka:大规模的企业应用通常会产生大量的日志,kafka可以为增长的日志削峰填谷
- logstash: 将kafka的日志数据作为input,通过grok、oniguruma、mutate等过滤器将异构数据解析为结构化数据,最终存储到Elasticsearch
- Elasticsearch:热门开源的搜索引擎,建立在 Apache Lucene 之上,在当前场景用于存储结构化的日志数据
- kibana:用于检索和管理ES数据的UI界面
我们将在本文一步步介绍我们在使用过程中遇到的问题,配置的优化,如何确保filebeat部署在业务主机上对业务的影响降到最低,如何使用cgroup来限制filebeat的系统资源使用配额!
问题场景
有些文章说filebeat的内存消耗很少,不会超过100M,这是没有针对场景和没有经过测试不严谨的说法(刚开始我们也没有完全覆盖所有情况进行测试,当然部分偶然情况有时无法预知),当真正按照默认的简单配置将filebeat部署到生产环境,或者某个参数配置错误,都可能会出现意想不到的问题,轻则影响服务的整体性能,重则可能造成应用被OOM-killer导致业务中断。我们在刚开始使用filebeat时,觉得这个组件已经如此成熟,应该问题不大。所以使用了最简单最基本的配置将其部署,为后来的问题埋下了祸根!
我们在实际使用中的确遇到了如下问题:
- Filebeat内存爆增至数GB、导致业务服务器触发OOM-killer,将业务进程kill掉
- 平常不会很频繁,但一旦压测或者有大量异常时就会出现以上问题
来看几个问题样本:
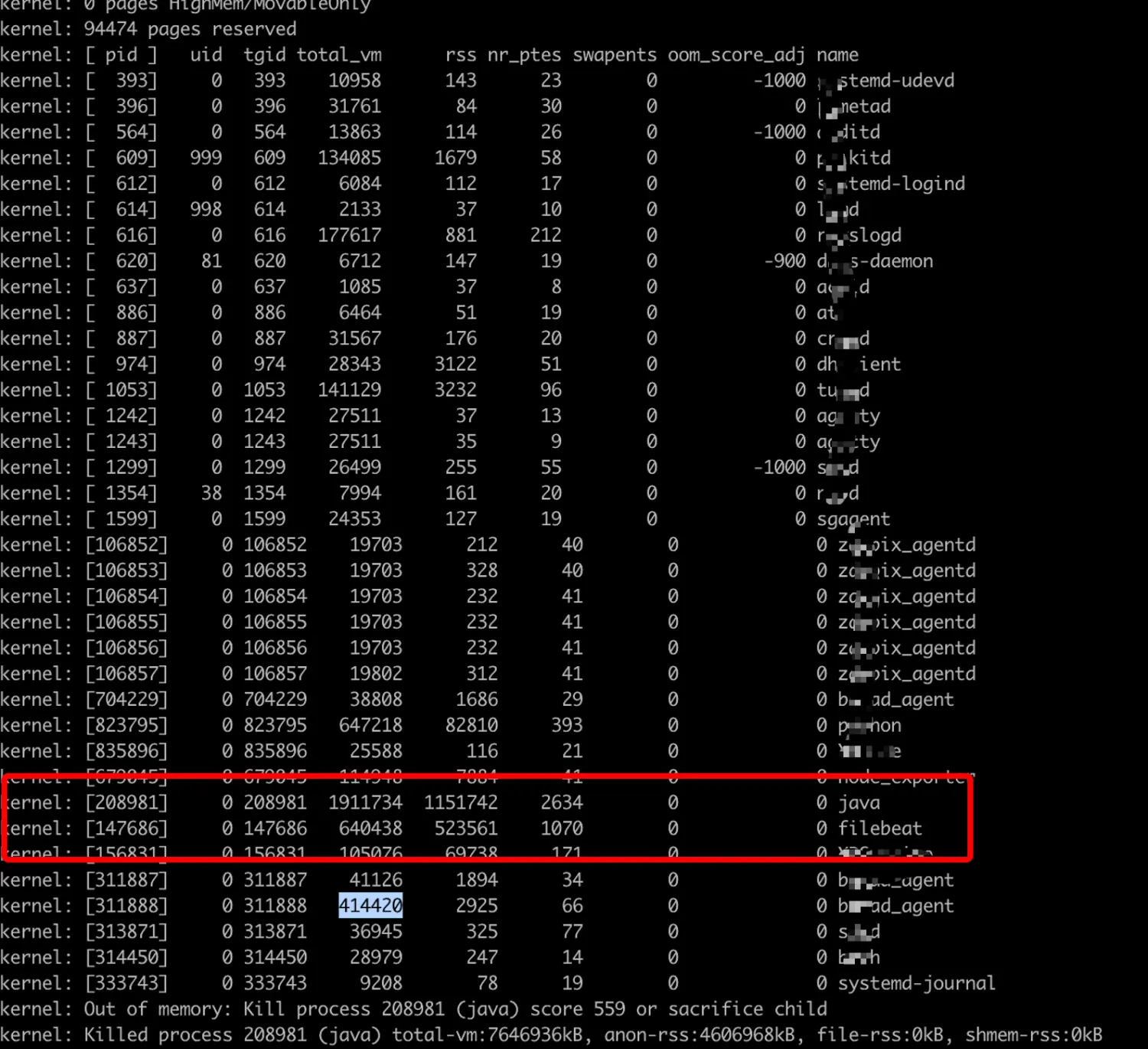
这里是filebeat导致Linux OOM 的一个场景,可使用
dmesg -T查看,这里可以看到,在OOM时,filebeat大概占用523561*4k ~= 2G(rss是内存页数,乘上内存页大小4k就是实际物理内存)(多的时候有过5G,比如有的日志文件中打印了很多二进制内容)
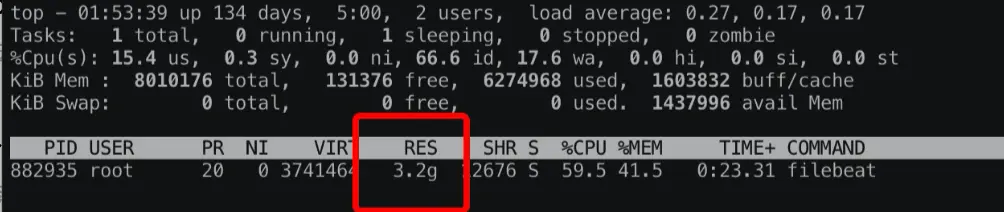
使用业务问题样本日志进行的测试的结果
初版filebeat.yml配置
这是初版的配置文件,相对简单,基本没有做什么特殊的配置:
这是一个错误的样本配置,请不要使用
1 | #=========================== Filebeat inputs ============================= |
初期的问题和调整:
我们接收业务反馈CPU占据到了300%上下(四核),并且偶现开头出现的OOM现象。
经过文档的查阅,发现几个明显的配置问题,并针对其做过一次初步的优化
max_bytes:单行日志的大小,默认为10Mqueue.mem.events:内存队列的大小默认为4096,有这个一个公式max_bytes * queue.mem.events等于约占的内存量,这里默认10M * 4096=40G,再考虑到队列存储已经编码为json的数据,则原始数据应该也会存储在内存中,那满打满算就得有80G内存占用,即使不存储原始日志,日常的服务器也难以接受这40G的内max_procs:没有限制CPU内核数使用,在日志较频繁时可能导致CPU满载ignore_older:由于服务器上有历史日志,可以使用此选项忽略较旧的文件
初步调整:
1 | max_procs: 1 # *限制一个CPU核心,避免过多抢占业务资源 |
问题反复及之后的处理
上面的改动,以为已经控制住问题,但是在不久之后还是反复出现了多次同样的OOM问题
filebeat限制单条消息最大不能超过20k,默认内存队列存储4096条记录,再加上明文日志,最高内存理论最高值在 20k * 4096 * 2 = 160M 左右浮动,即使做了以上限制,还是不时出现内存爆增的情况
一时没有找到问题解决方案,我们做了如下的几个阶段策略:
阶段一:降低非预期情况下对应用的影响
阶段二:重新梳理和优化配置,达到优化内存的目的
阶段一:降低非预期情况下对应用的影响
降低非预期情况下对应用的影响,是将filebeat进程的oom_score_adj值设置为999,在出现意外情况时OOM也优先 kill 掉filebeat,从而达到即使出现意外情况,也不会影响到业务进程
具体的操作是:
启动filebeat -> 获取进程PID -> 写入/proc/$pid/oom_score_adj 为999
OOM killer 机制一般情况下都会kill掉占用内存最大的进程,在kill进程时,有个算分的过程,这个算分过程是一个综合的过程,包括当前进程的占用内存情况,系统打分,还有可由用户控制的oom_score_adj分值,将影响整体算分。
oom_score_adj的取值范围是 -1000 至 1000,值越大,OOM在kill时会优先kill掉此进程,为了最大限度让系统kill掉filebeat,我们必须将此值调整到最大
阶段二:重新梳理和优化配置,达到优化内存的目的
针对多次问题的场景,进行样本的提取,发现多次问题出现的都是在大量的堆栈异常日志中出现,怀疑是多行合逻辑不对导致的问题:
下面我们来着重看一下多行最初配置:
1 | multiline: # 多行匹配日志 |
发现官网对于此参数的默认值是5s,但是现在却被误配置成了30s,肯定是有问题的啦

问题的原因应该就在 multiline.timeout这个参数之上,我们尝试调整多次参数的大小进行测试:
1 | # 由于样本不同,可能内存量也会有所不同,这里选取的是在业务服务中有大量错误堆栈的日志进行测试 |
我的对官方的这句话的理解是:
超时时间后,即使还未匹配到下一个多行事件,也将此次匹配的事件刷出
如果日志中如果包含很多错误堆栈,或者不规范的日志大量匹配多行逻辑,会产生过多的多行合并任务,但是超时时间过长,过多的任务就会最大限度的匹配和在内存中等待,占用更多的内存!
除此以外我们也做了其他调整包括但不限于如下:
queue.mem.events:从默认的4096 设置到了2048
queue.mem.flush.min_events: 从默认2048设置到了1536
multiline.max_lines:从默认500行设置到了200行
最后我们的最优配置如下,在调整之后将问题样本进行测试,内存只占用350M~500M之间:
1 | #=========================== Filebeat inputs ============================= |
使用cgroup限制资源用量
对于我们的业务机器来说,让filebeat独占一个CPU去进行日志收集,显然不被业务人员所接受,因为在业务高峰期日志量会很大,filebaat进行大吞吐量的日志收集、多行合并、消息发送;很有可能会限制业务的性能,可能没有filebeat我原本需要10台主机,但是有了filebeat我就需要15台主机来承载高峰业务。
上面的配置虽然已经基本控制住内存用量,但也有可能出现不同的不可预期的情况导致内存增长
我们该如何限制CPU使用量和应对意想不到的内存增长情况?
答案是:绝对性的控制CPU/内存在一个范围内,我们可以使用cgroup来实现
什么是cgroup?
cgroups 是Linux内核提供的一种可以限制单个进程或者多个进程所使用资源的机制,可以对 cpu,内存等资源实现精细化的控制,容器 Docker 技术就使用了 cgroups 提供的资源限制能力来完成cpu,内存等部分的资源控制。
另外,开发者也可以使用cgroup提供的精细化的控制能力,来限制某一组/一个进程的资源使用,比如我们的日志agent需要部署到应用服务器,为了保证系统稳定性,可以限制agent的资源用量在合理范围。
由于篇幅限制,这里对cgroup就不多做介绍了,只说如何使用起来,如果有不明白的,可以查看下方参考链接
如何使用cgroup
cgroup相关的所有操作都是基于内核中的cgroup virtual filesystem,使用cgroup很简单,挂载这个文件系统即可。一般情况默认已经挂载到/sys/fs/cgroup目录下了
mount | grep cgroup 查看系统默认是否挂载cgroup,cgroup包含很多子系统,用来控制进程不同的资源使用,我们只用其中cpu和memory这两个
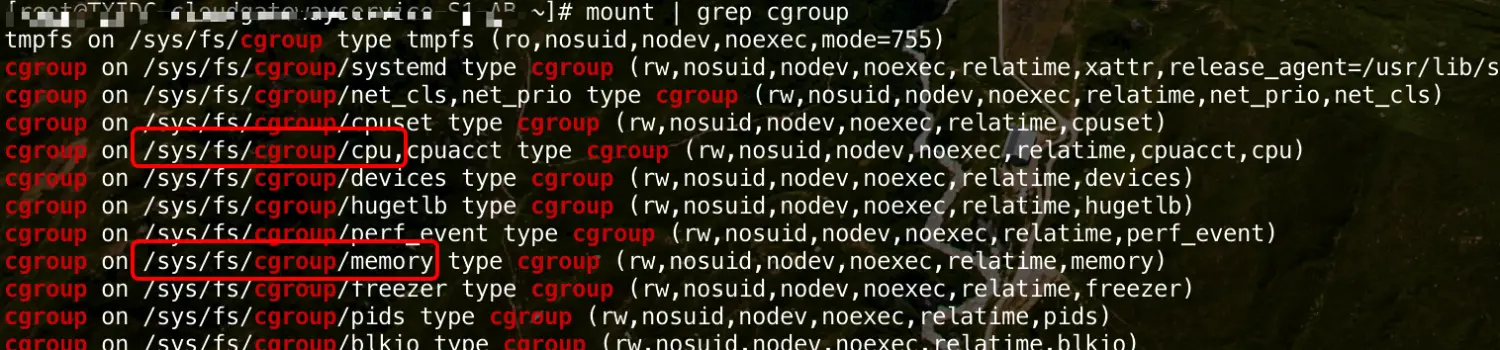
用到的cgroup的子系统:
- cpu 子系统,主要限制进程的 cpu 使用率
- memory 子系统,可以限制进程的 memory 使用量
创建子cgroup
- 如果需要限制cpu,则在已挂载的
/sys/fs/cgroup/cpu子系统下建立任意目录,如filebeat_cpu - 如果需要限制内存,则在已挂载的
/sys/fs/cgroup/memory子系统下建立任意目录,如filebeat_memory
filebeat_cpu和filebeat_memory下都会自动生成与上级目录相同的文件,我们重点关注一下几个文件
1 | filebeat_cpu |
改造我们的filebeat启动脚本,支持在启动后限制内存和cpu:
restartFilebeat.sh
1 |
|
限制:
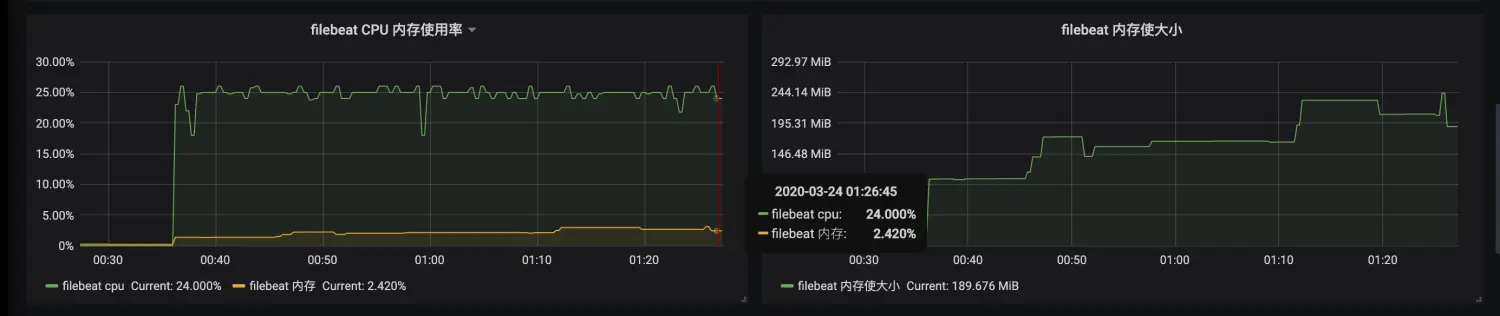
CPU -> 单核25%
内存 -> 500M,大于此值则触发cgroup的OOM-killer机制
优化前优化后的对比
优化前:
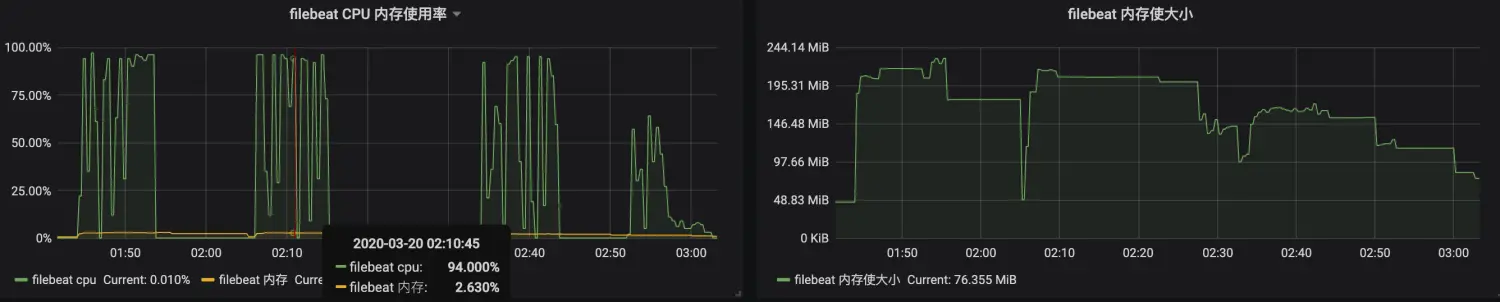
优化后:
参考
本文标题:记Filebeat系统资源使用优化
文章作者:AwesomeYang
发布时间:2020-03-26
最后更新:2024-04-21
原始链接:https://struy.cn/2020/03/26/filebeat-cpu-and-mem-limit/
版权声明:未经允许禁止转载,请关注公众号联系作者
